

模型
剑指 Meta:Mistral Large2 凌晨开源,媲美 Llama3.1
Overseas 发表了文章 • 2024-07-25 11:58
Mistral AI 发布 Mistral Large 2,123B 大小,128k 上下文,与 Llama 3.1 不相上下。
支持包括法语、德语、西班牙语、意大利语、葡萄牙语、阿拉伯语、印地语、俄语、中文、日语和韩语在内的数十种语言- 支持 Function Calling 和 Retrieval
开源地址: https://huggingface.co/mistralai/Mistral-Large-Instruct-2407 可用于研究和非商业用途,商用需获取许可
在线使用:https://chat.mistral.ai/chat
开发者平台:https://console.mistral.ai/
云服务:可在 Google Cloud 、Azure AI Studio、Amazon Bedrock 和 IBM watsonx.ai 上调用
简单使用
可在这里使用:https://chat.mistral.ai/chat

不够聪明啊,ahhhhhh
版本特色
- 多语言设计:支持多种语言,包括英语、法语、德语、西班牙语、意大利语、中文、日语、韩语、葡萄牙语、荷兰语和波兰语。
- 精通代码:熟练掌握 80 多种编程语言,如 Python、Java、C、C++、JavaScript 和 Bash 等。还熟悉一些更具体的语言,如 Swift 和 Fortran。
- Agent 支持:原生支持 Function Calling 和 JSON 输出。
- 好的推理:数学和推理能力远超前代,与 GPT-4o、Claude 3 Opus 和 Llama 3.1 405B 不相上下
- 128k 上下文:,加之在 la Plateforme 实施的输出限制模式,大大促进了应用开发和技术栈的现代化。
- 开源许可:允许用于研究和非商业用途的使用和修改。
推理测试
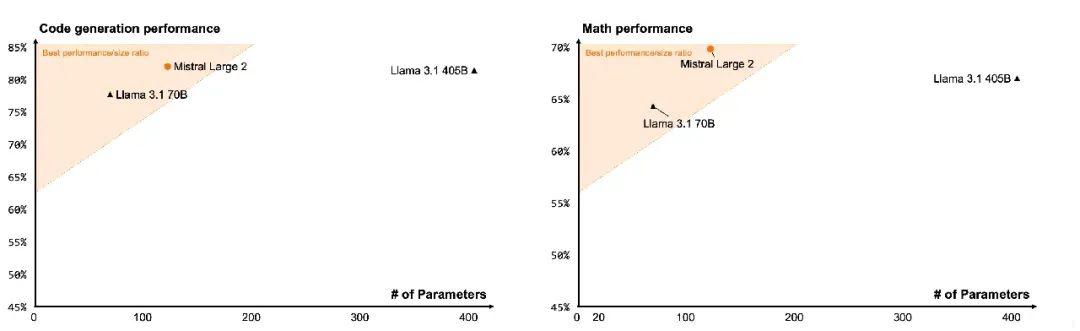
表现远超之前的 Mistral Large,与 GPT-4o、Claude 3 Opus 和 Llama 3.1 405B 相媲美
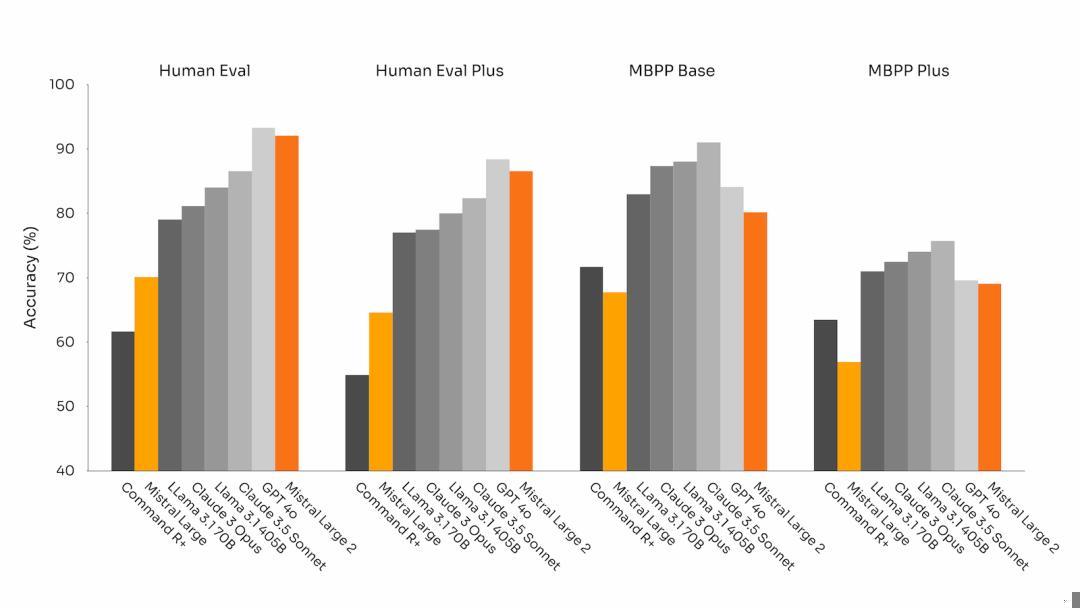
代码生成测试
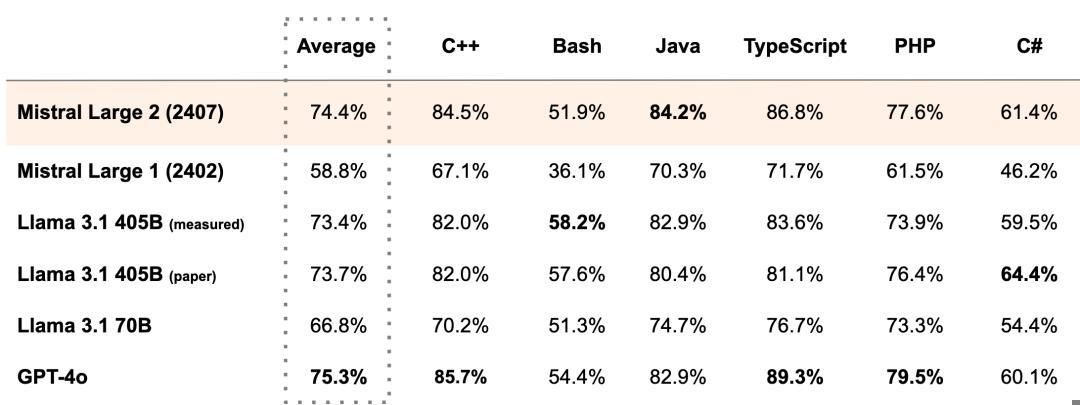
MultiPL-E 性能测试
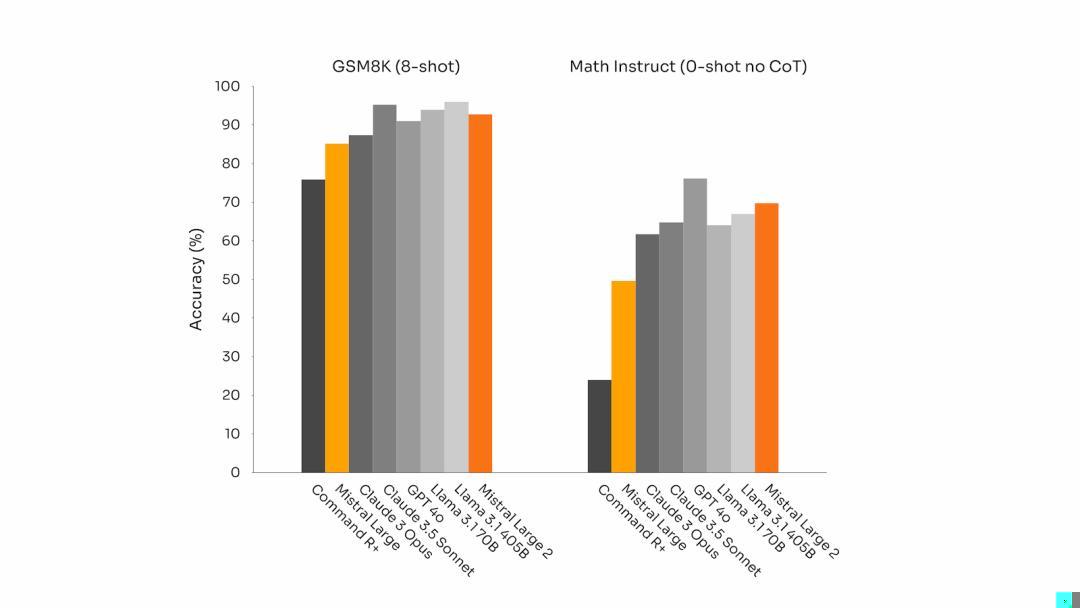
GSM8K(8-shot)和 MATH(0-shot,无 CoT)测试
语言覆盖
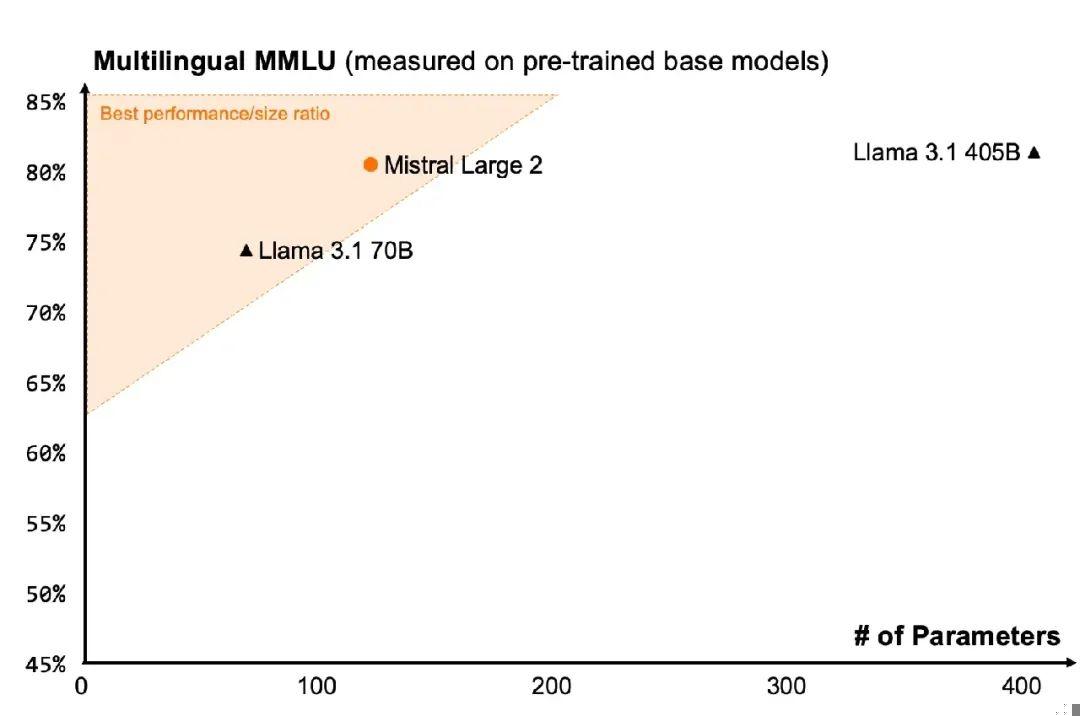
官方给的图,剑指 Meta
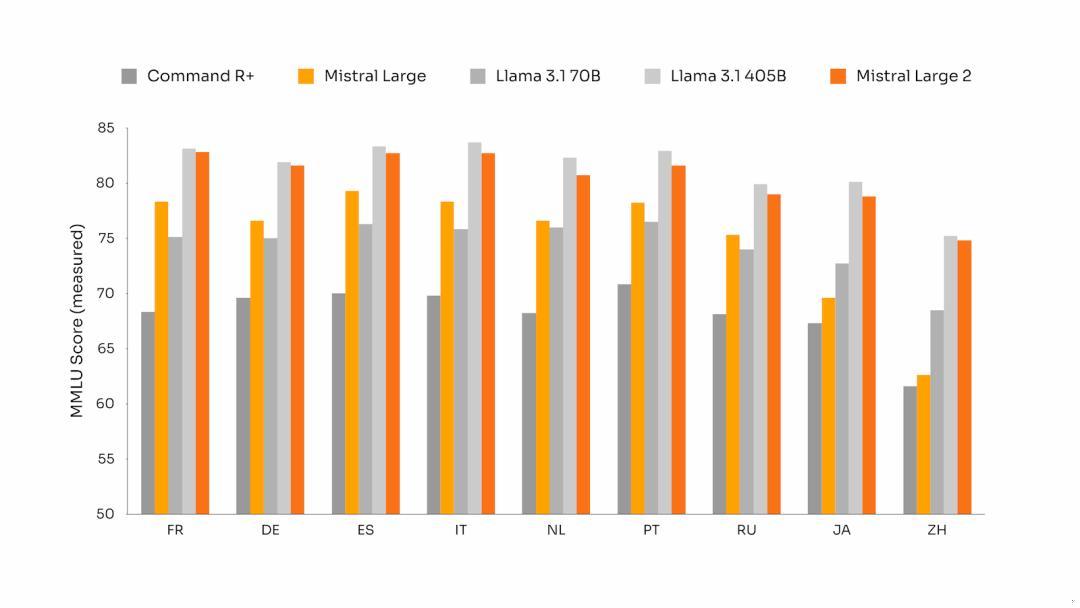
语言性能测试
更多信息
按 Mistral 的说法,他们会围绕以下模型在 la Plateforme 上进行后续整合:
- 通用模型:Mistral Nemo 和 Mistral Large
- 专业模型:Codestral 和 Embed
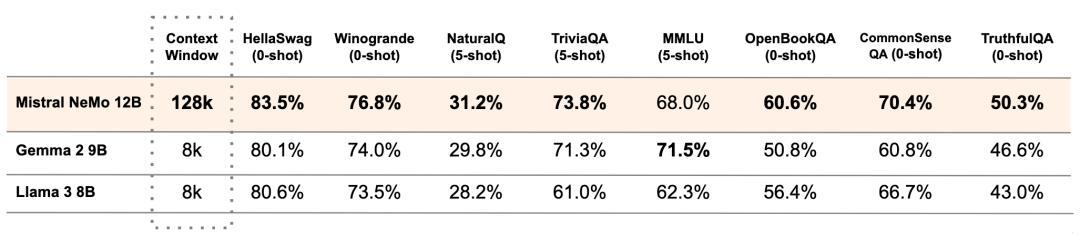
其中 Mistral NeMo 是一款与 NVIDIA 合作开发的 12B 模型,一周前发布的,具体参见:https://mistral.ai/news/mistral-nemo/
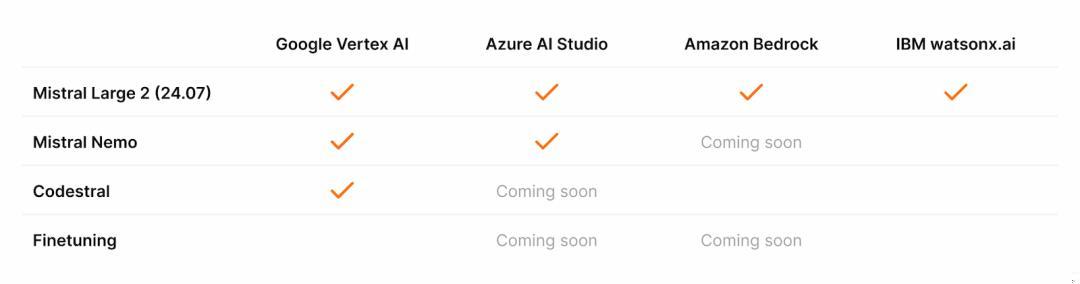
同时,Mistral 的 Large2 模型已可在 Google Cloud 、Azure AI Studio、Amazon Bedrock 和 IBM watsonx.ai 上进行调用。更多的安排参考:
普大喜奔!免费使用 llama3.1的八个网站
Overseas 发表了文章 • 2024-07-25 10:58
又一个重量级大模型发布,波谲云诡的AI江湖再添变数
这是一款强大的开源 AI 模型,由知名科技公司 Meta(之前叫 Facebook)发布。Llama 3.1 ,一共三个版本, 包括 8B、70B、405B
今天我向您简介这款AI,并分享八个免费使用 Llama 3.1 的方法,其中3个国内直联、支持405B!
以下是官方公布的测试数据,水平 与gpt4o、claude3.5 sonnect 旗鼓相当
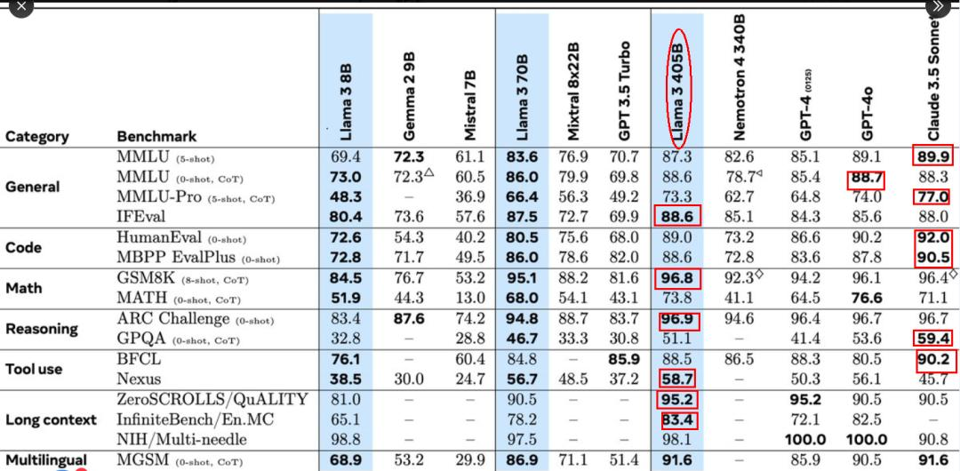
第三方评测机构,除坚持用户盲测打分的LMsys暂未给出排名外,SEAL 和 Allen AI 的 ZeroEval 两个独立评估机构给出了自己的结果,405B 确实厉害!SEAL 上405B指令遵循主流AI中第一、代码第四、数学第二
ZeroEval 测试它整体性能介于 Sonnet 3.5 和 GPT4o 之间。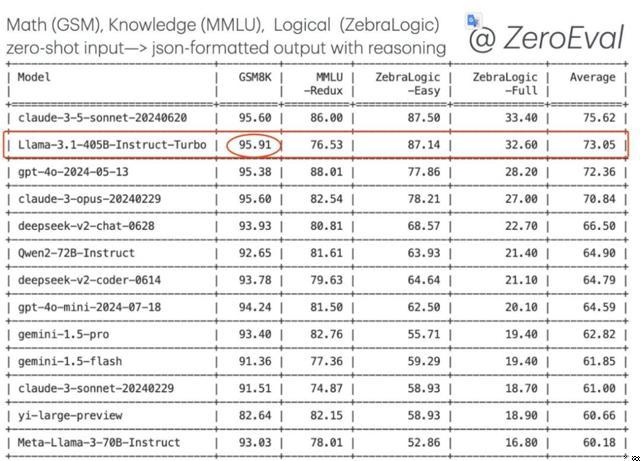
官方博客: llama.meta.com/llama3
申请下载: llama.meta.com/llama-downloads
一、开源 AI 和闭源 AI 大战
在 AI 的世界里,有两个阵营:开源 AI 和闭源 AI。开源 AI 像是一个巨大的图书馆,任何人都可以进去学习、分享和改进知识。闭源 AI 则像是私人图书馆,只有特定的人才能进入。什么是开源呢?就是代码和数据是公开透明的,任何人都可以下载使用和改进。开源 AI 模型和普通商业 AI 模型不太一样。开源的好处是,大家可以一起分享知识,互相合作改进模型。成本也会更低,让更多人和小型公司参与进来。而且开源的模型更加透明,人们更容易相信和信任。相比之下,商业 AI 模型的代码和数据都是保密的,只有公司自己掌控,定价也更高。但这样可以提供更专业定制的服务。
开源 AI 的优势:
共享与协作:全球的研究者和开发者可以一起工作,让模型变得更好。
SEAL 上405B指令遵循主流AI中第一、代码第四、数学第二
ZeroEval 测试它整体性能介于 Sonnet 3.5 和 GPT4o 之间。
官方博客: llama.meta.com/llama3
硬件配置 要求中等,下载到本地,苹果M1、16G显卡就能本地运行后,免费使用!
让我们一起来看看 llama3.1是如何改变游戏规则的,以及我们个人用户如何能够使用它。
关键是,如果你有能力本地部署,它还是完全免费的!
在 AI 的世界里,有两个阵营:开源 AI 和闭源 AI。
什么是开源呢?就是代码和数据是公开透明的,任何人都可以下载使用和改进。
相比之下,商业 AI 模型的代码和数据都是保密的,只有公司自己掌控,定价也更高。但这样可以提供更专业定制的服务。
- 共享与协作:全球的研究者和开发者可以一起工作,让模型变得更好。
- 成本效益:不需要很多钱就能使用这些模型,小公司和个人也能参与。
- 透明度:我们知道它是如何工作的,这让我们更信任它。
主流AI大模型速度-性能- 价格分布图如下:
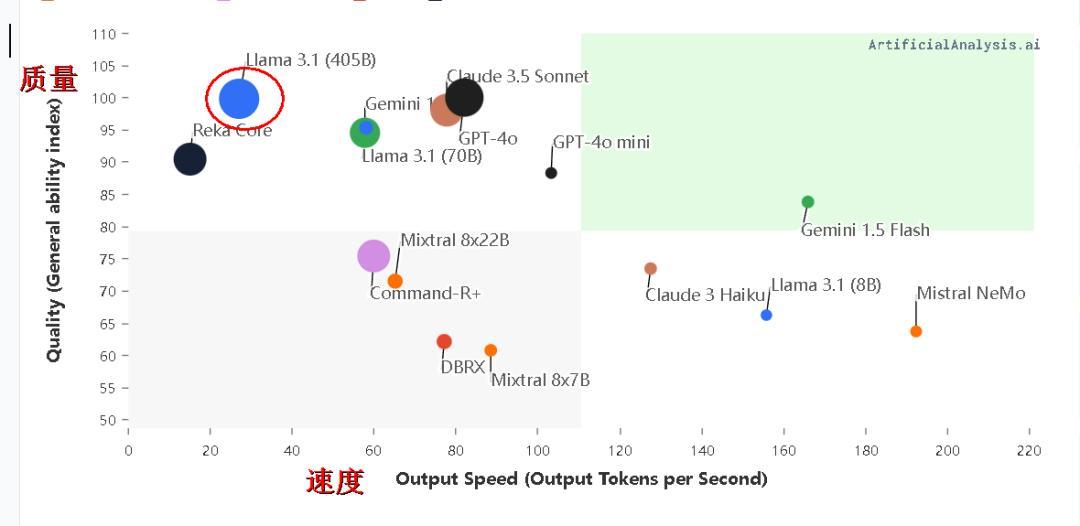
闭源 AI 的特点:
- 专有技术:由一家公司控制,他们不告诉别人它是怎么做的。
- 定制化服务:可以提供特别为你设计的服务。
- 盈利模式:通过订阅费或授权使用费来赚钱。
常见闭源软件有 ChatGPT、Claude、谷歌 gemini、kimi 等
meta 是一个商业盈利机构,但是为了构建元宇宙,它买了最多的显卡,给大家训练了一个开源 AI 大模型 llama 系列!
二、llamma3 的使用
现在,让我们看看如何使用 llama3.1。
(一)本地使用:
- ollma 部署:如果你想在自己的电脑上使用 llama3,可以下载模型并进行本地部署。
1、安装和启动 Ollma
访问 https://ollama.com/download
下载适合自己系统的 Ollma 客户端。
2、运行 Ollma 客户端,它会在本地启动一个 API 服务。
在 Ollma 中,可以选择运行 LLaMA 3.1 模型
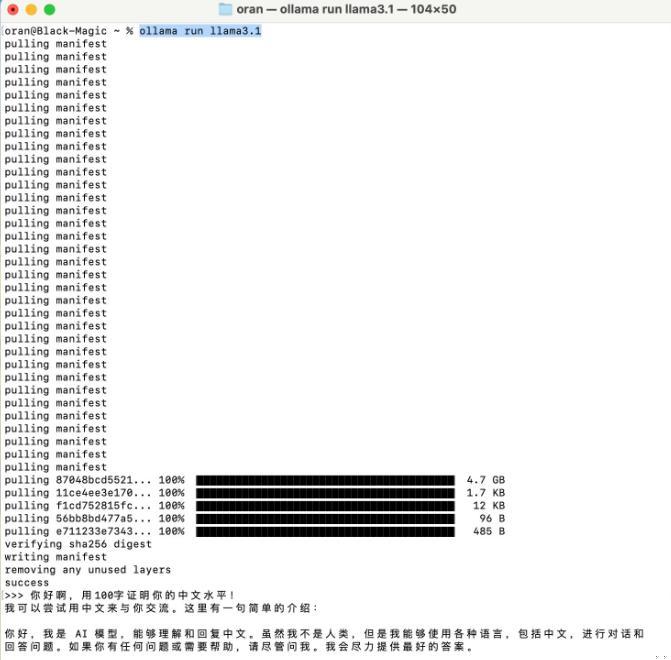
打开终端,输入:ollama run llama3.1
3、输入问题,开始使用
本地API使用 :
到第三方去购买API,然后在本机安装一个chatnextweb软件。
第三方API的价格目前是gpt4o的50%,大概2.5~3美元每百万token。
(二)在线使用
1、Meta 官网
国内直联:否
登录难度:极大
登录网址:www.meta.ai
响应速度:中等
2、抱抱脸 HuggingChat(推荐)
国内直联:否
登录难度:中
登录网址:huggingface.co/chat/
响应速度:中等
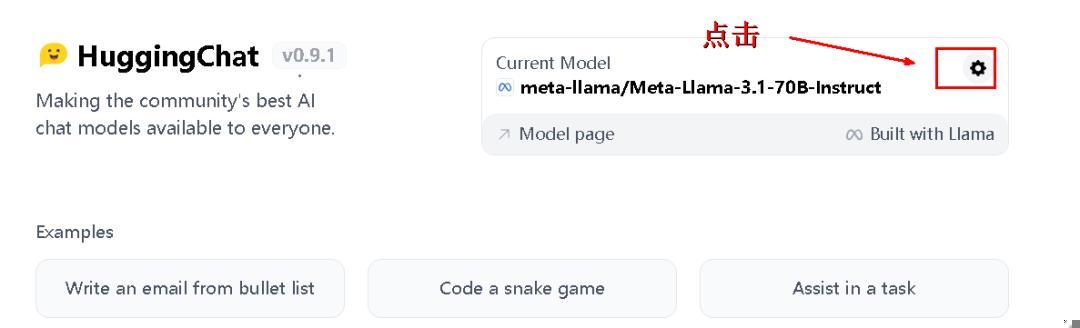
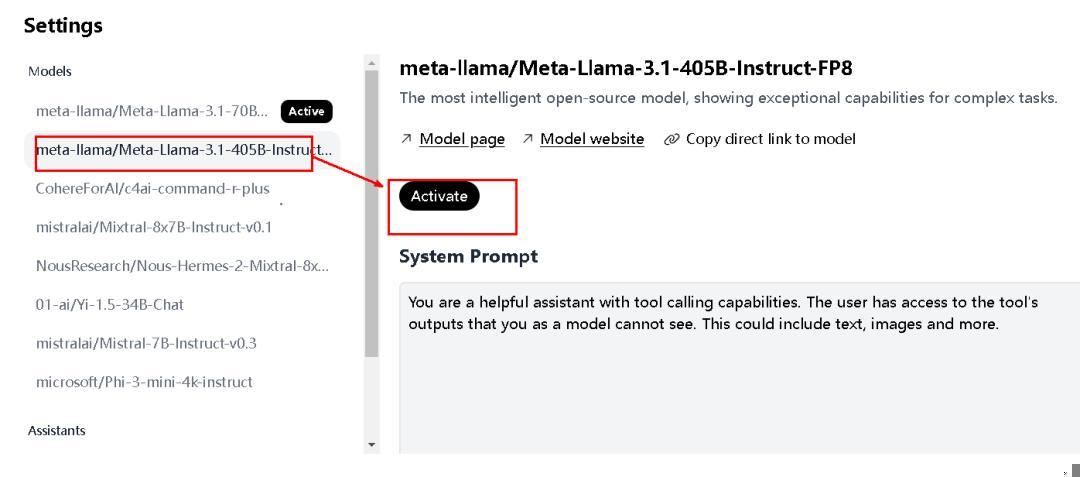
打开界面上的“设置”齿轮,选中 LLaMA3.1,点击“Activate”,输入系统提示“用中文回复”,关闭窗口,搞定!
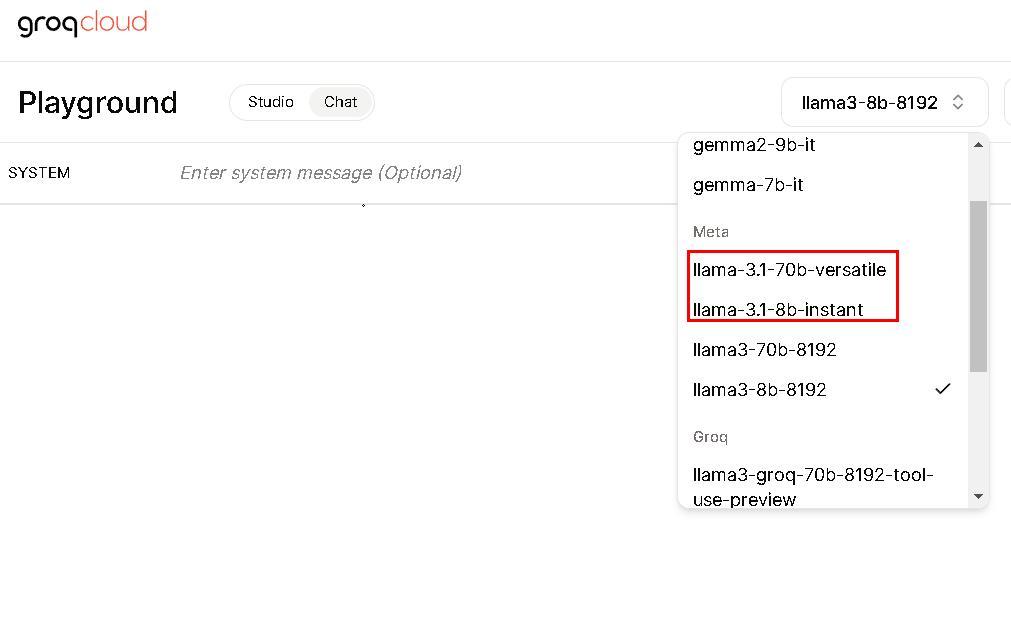
3、Groq 平台
Groq 是一家专注于开发高效能 AI 推理硬件的公司,其产品旨在为机器学习工作负载提供高性能和低功耗的解决方案,开发了一种名为LPU的专用芯片,专门针对大型语言模型(LLM)的推理进行优化。
国内直联:否
登录难度:中
登录网址:console.groq.com
响应速度:中等
使用界面:
需要选中 LLaMA-3.1,405B暂时下架,估计过两天会恢复
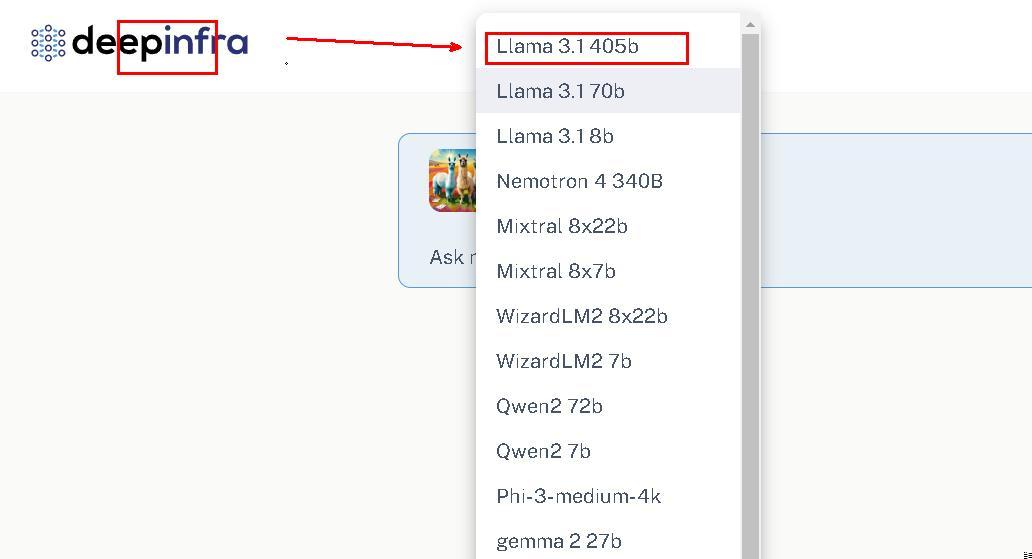
4、deepinfra 平台
DeepInfra 是一个提供机器学习模型和基础设施的平台,它专注于提供快速的机器学习推理(ML Inference)服务。注册送1.5美元API 额度。也可在线使用
国内直联:否
登录难度:中
登录网址:deepinfra.com/meta-llama/
响应速度:中等
使用界面:
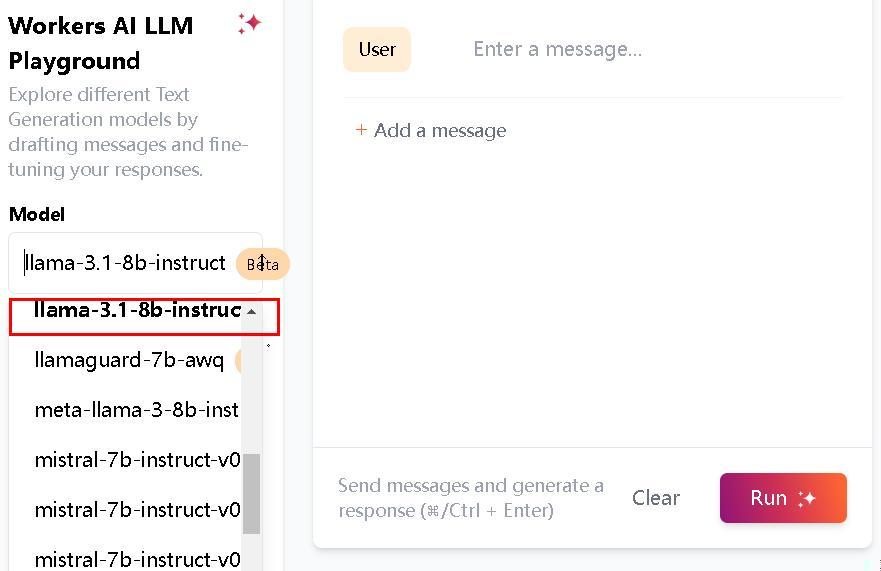
5、cloudflare 平台(国内直联)
Cloudflare 是一家大名鼎鼎提供互联网安全、性能优化和相关服务的公司
国内直联:是
登录难度:中
登录网址:
playground.ai.cloudflare.com/
响应速度:中等
使用界面:
需要选中 LLaMA-3.1 ,目前只有 8B 版本
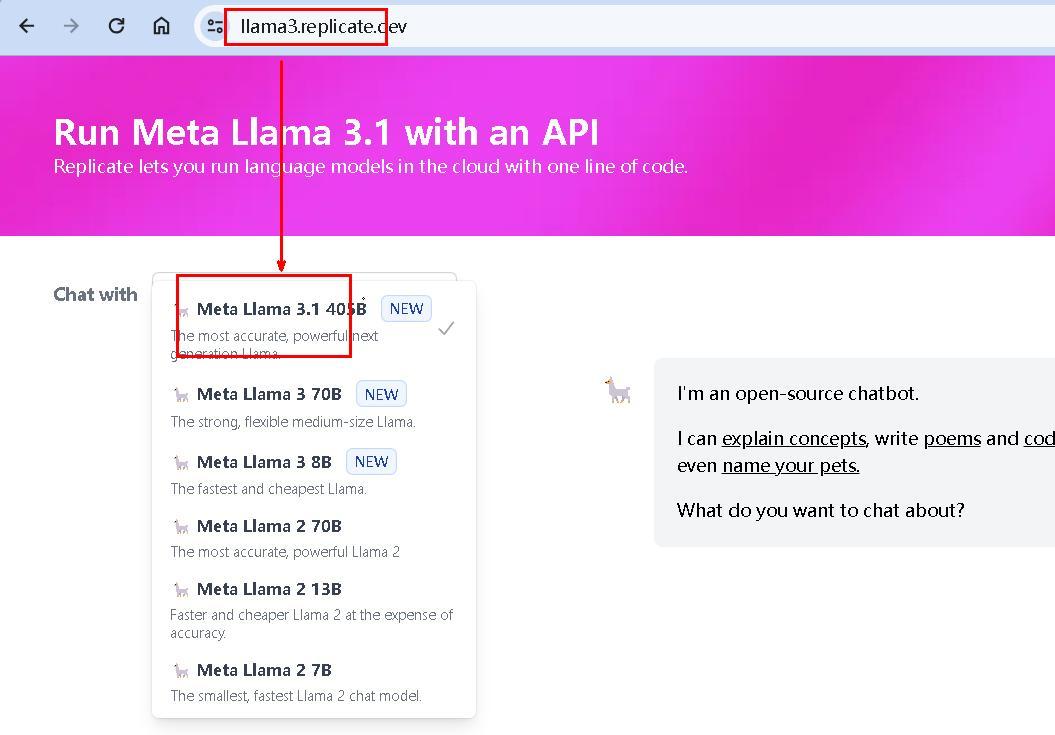
6、Repilcate 平台(推荐,国内直联)
国内一个面向机器学习和人工智能模型的在线平台,专注于提供模型的部署、运行和训练服务
国内直联:是 :)
登录难度:小,国内直联,支持405B
登录网址:llama3.replicate.dev
https://replicate.com/meta/meta-llama-3-70b-instruct
响应速度:中等
使用界面:
需要选中 LLaMA-3.1
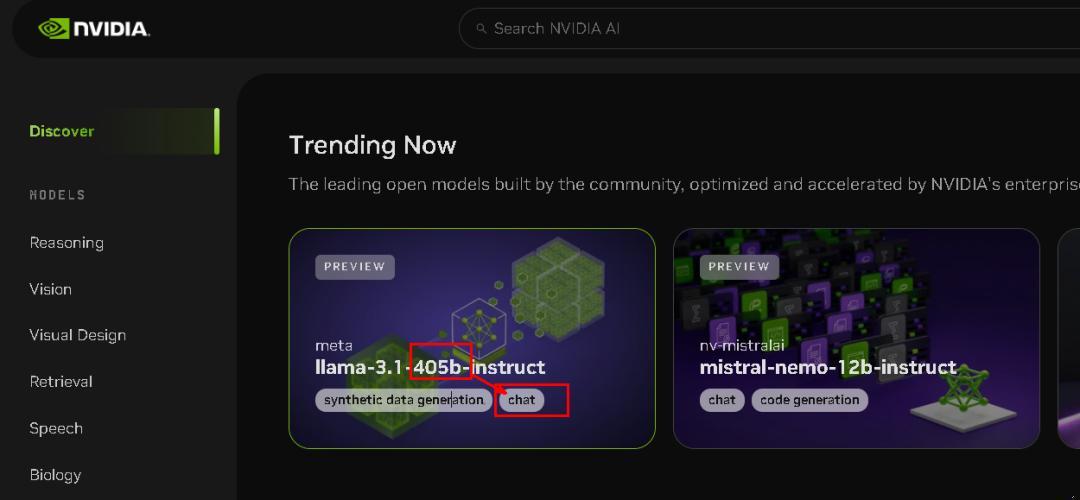
7、英伟达平台(国内直联)
英伟达公司不用介绍了吧
国内直联:是 :)
登录难度:小,,国内直联,支持405B
登录网址:
https://build.nvidia.com/explore/discover#llama-3_1-405b-instruct
响应速度:中等
使用界面:
需要选中 LLaMA-3.1
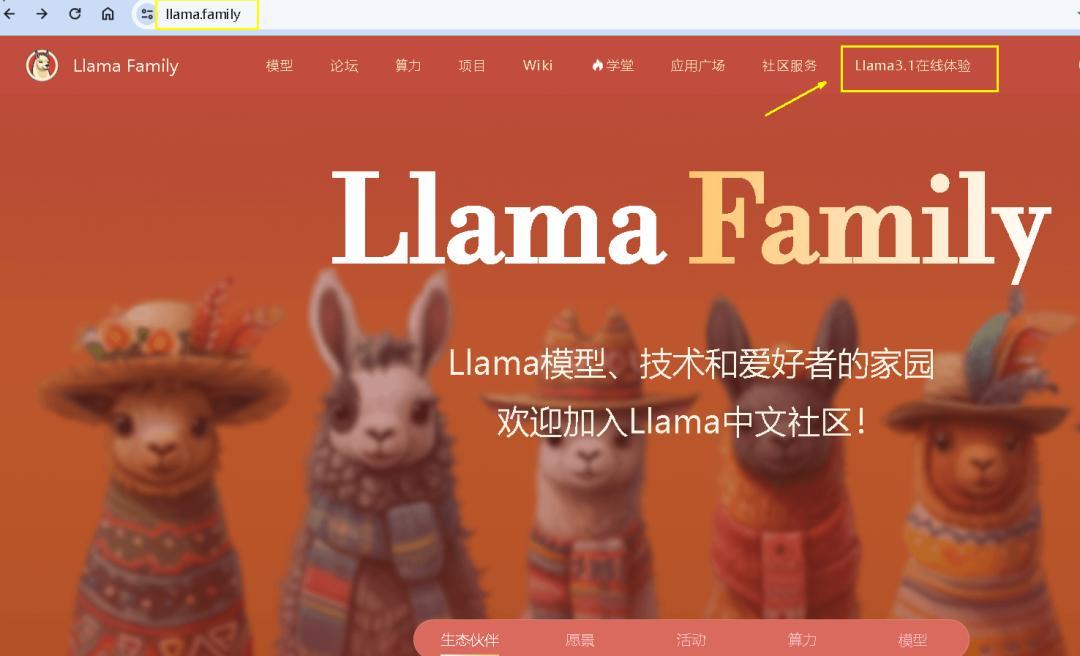
8、中文 llama 社区(国内直联)
中文 llama 社区
国内直联:是 :)
登录难度:小,国内直联,支持405B
登录网址:llama.family/chat
响应速度:70B(8B 很快)
使用界面:
这次 llama3.1 的发布,就看其他厂商如何应对了,估计 AI之王 GPT5 快出关了!
好啦,今天的分享就到这里!
Google 全新 AI 模型「Gemini」推出,30 项测试都赢过 GPT-4v,比专家还强
newsman 发表了文章 • 2023-12-25 18:03

Google 的 Bard AI 机器人过去曾使用 LaMDA 系列的语言模型,后来改为 PaLM2,如今正式宣布推出自家的语言模型 Gemini,使用 TPU v4 和 v5e 芯片进行训练,强调多模、多样化的解析能力以及运行效率,甚至在多项测试中赢过 OpenAI 的 GPT-4 模型。
Google 自家原生 AI 模型,多项测试赢过 GPT-4v
Gemini 是 Google 推出的「原生」AI 模型,可以处理包含代码、文本、声音、图片、影片这些不同形式的内容,而且因为 Google 的数据库中有着巨量的内容,是训练 Gemini 很棒的资源。
Google 甚至表示 Gemini 可以直接「看懂」图片,而不是像过去使用 OCR 的方式扫描图片然后再辨识上面的文本这种方式来分析图片。
在 Google 的影片中,拿了两张图片做比较,Gemini 可以回答右边图片中的汽车会跑的比较快,因为符合空气力学的关系,但你可以注意到,图片中并没有任何的文本,如果使用传统 OCR 解析图片的方式,就无法判断出这些内容。

Google 展示的内容中,甚至还直接画了一只鸭子,而 Gemini 也可以很快地理解出用户话的内容是什么。

Gemini 也能够解析代码、C++、Java 等常用编程语言,甚至是爬虫都可以,不只分析,也能够按照你要的需求、指定的语言生成代码。

Gemini 的运行速度也相当快,在一个午休的时间就可以阅读完 20 万份的论文,并且从用户要求的关键字、条件去查找相关的数据,找出 250 份符合资格的论文以及我们要找的数据在哪里,并且整理成一份清单。
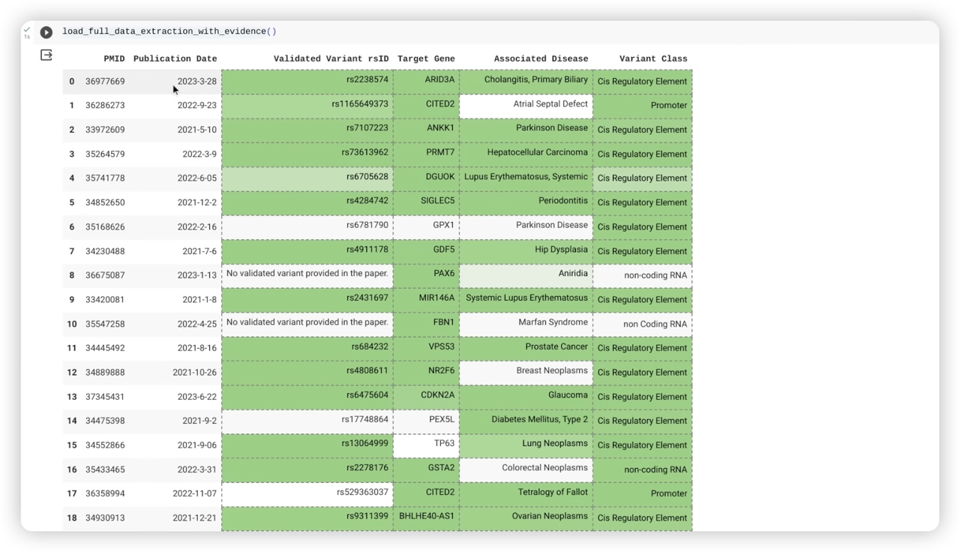
如果拿来和 OpenAI 的 GPT-4v 和 Gemini 做比较,全部 32 项测试中,有 30 项测试是由 Gemini 胜过了 GPT-4v,而且在 MMLU 大规模多任务语言理解的测试中,包含了历史、法律、医学、数学….等 57 个科目中,Gemini 都有达到 90% 的水准,甚至超越了人类专家的表现。
Gemini 也有适合手机使用的版本,Pixel 8 Pro 优先体验
Gemini 共有 3 种不同大小的模型版本,分为 Ultra、Pro、Nano,其中的 Nano 版本最小,甚至可以直接安装到手机上使用,Google 也表示 Nano 版本就针对行动设备所打造的,旗下 Pixel 8 Pro 也会优先开放使用。
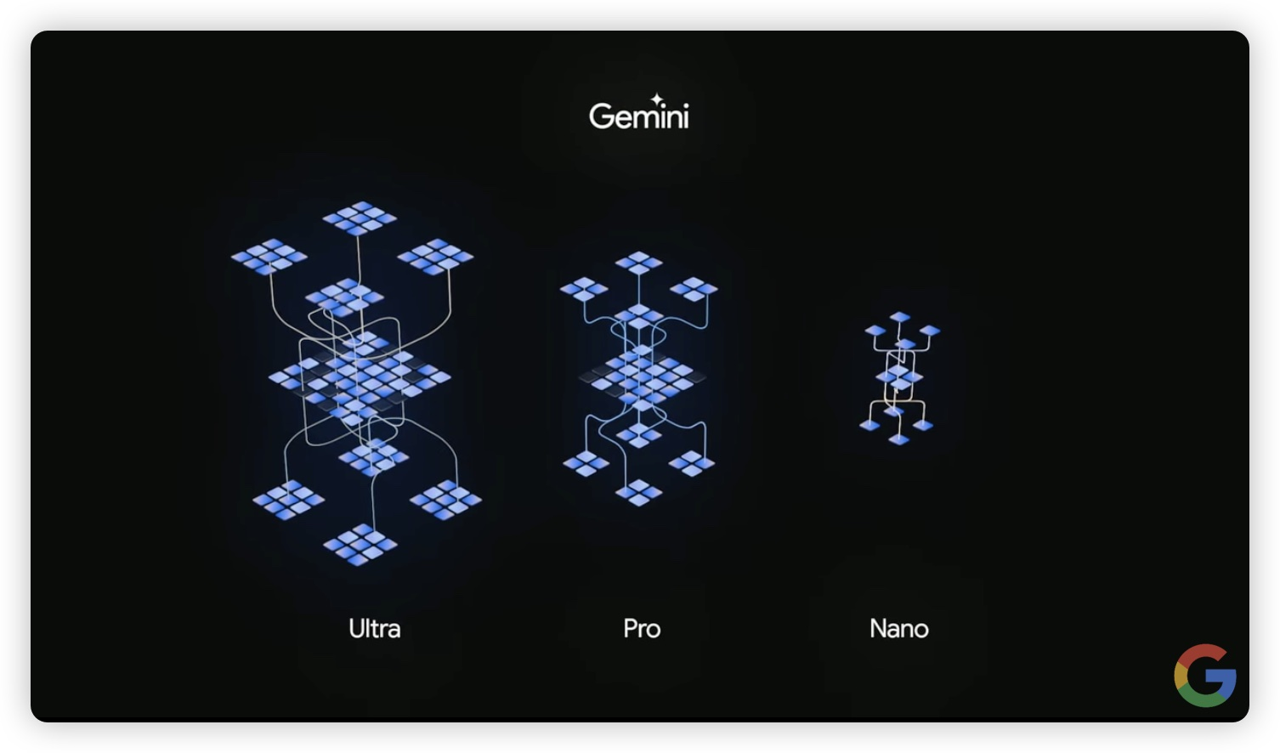
其中最大型的 Gemini Ultra 也就是上面所说,在 32 项测试中赢过 GPT-4v 其中 30 项的大型版本,预计明年推出,但在此之前将会先提供给部分用户、开发者以及企业用户。
而中型的 Pro 版本则是现在就可以使用,部分使用英文语系的用户在使用 Bard 的时候,就会自动用上 Gemini 模型,12/13 Google Cloud 的 Vertex AI、AI Studio 上也会释放出相关的 API。
国内AI绘图工具大PK:商汤秒画、阿里通义万相和百度文心一格,谁的绘图效果更惊艳?
newsman 发表了文章 • 2023-07-24 17:42

最近我也在试用国内AI大模型方面做得比较好的另外两家的AI文生图产品,他们就是商汤秒画和阿里通义万相,他们都是可以免费注册后使用的,使用起来没太多限制,很方便。再结合我之前推荐的百度文心一格也是免费的,今天咱们就来对比PK一下国内目前这三家的AI绘图能力,看谁画出来的图更好呢。
商汤秒画的访问地址是:https://miaohua.sensetime.com/zh-CN
通义万相的访问地址是:https://wanxiang.aliyun.com/
文心一格的访问地址是:https://yige.baidu.com/
好了,大家可以试下注册,注册好之后我们就来开始试用吧。
绘画技能PK
我们用一样的描述词,来看下三款工具的绘图效果。
1、先试下简短的词语:森林里的精灵
首先是商汤秒画的效果:

接下来是通义万相出场:

最后是文心一格出场:

这一轮,大家都把自己心目中的精灵画出来了,难分伯仲。
2、好,那第二轮换一个词:黑夜,北极星发出一束光照射到大海上,杰作,细节丰富,8K,HDR
商汤秒画:

通义万相:

文心一格:

也还是仁者见仁智者见智,各有优势。
3、再来一轮PK,描述词:万马奔腾
商汤秒画:

通义万相:

文心一格:

个人评价,这轮秒画后面许多马有些失真,万相的扬沙效果做得更好,而文心虽然马的细节做得挺好,但是没有画出万马的感觉。
3、再来一个需要一定的知识储备的吧,描述词:武松打虎。
商汤秒画:

通义万相:

文心一格:

这轮很明显,只有秒画get到了意思,万相有点闹着玩啊,文心至少画出了老虎,这轮秒画胜出。
4、之前看过网友用Midjourney生成各个朝代士兵自拍的图片,挺逼真的,这是效果图,今天我们也拿这三个国产AI绘图工具也来试试看,看跟目前最棒的AI工具的差距还有多少。

描述词:公元前1000年,一个秦朝的士兵对着镜头在自拍,穿着盔甲,开心地笑,旁边围着一群士兵,面对镜头也在笑,背景是城墙,上面飘着秦朝的大旗,杰作,细节丰富,HDR,8K画质
商汤秒画:

通义万相:

文心一格:

这轮看来,文心偏得有些多呀,秒画和万相虽然感觉不太像秦朝的士兵服装(我们通过秦始皇兵马俑的着装可以找到原版),但整体摄影感觉还是比较真实的。
5、最后,我们来试试他们的家居设计能力。描述词:现代简约家居设计,一个客厅,桌子,电视,茶几,阳台,沙发
商汤秒画:

通义万相:

文心一格:

整体来讲,都get到了描述词的点,但是个人观点,万相输出的设计更符合主流设计风格,电视机的摆放更合理些。
下面我来分别介绍下这三款AI绘图的使用方法:
商汤秒画
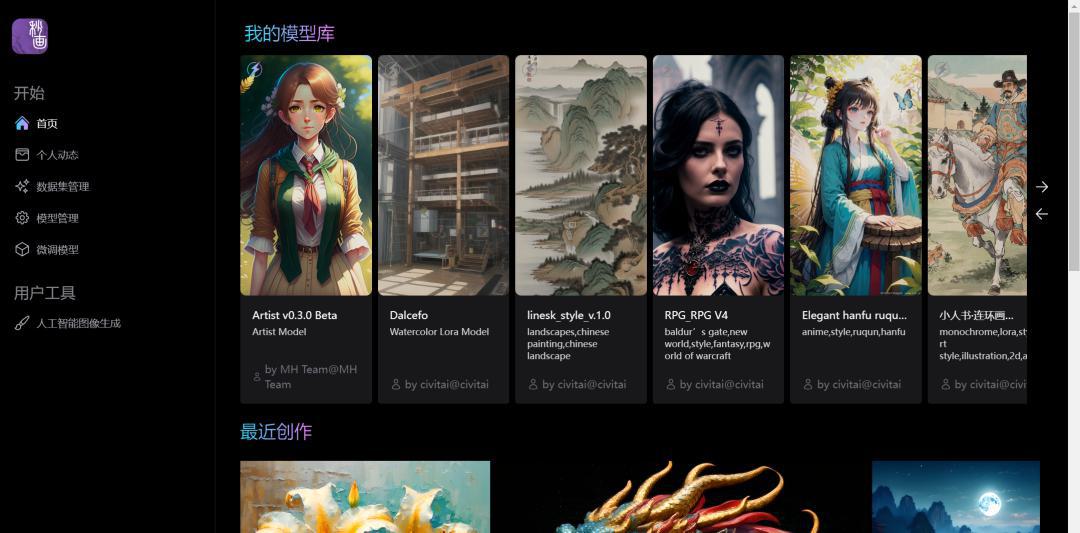
1、我们登录进来后,选择Artist v0.3.0 Beta模型进行绘画,这个是官方团队出品的。至于其他模型,是用户自己再通过一些特定数据集进行训练后的,有些擅长画水墨画、有些擅长出游戏人物,有的擅长画小人书,这个看个人需求。从通用性角度来看,还是官方模型效果最好。
2、我们可以选择一次生成的图片数量、分辨率比例、步数一般设置到最大100,画质效果最好。也可以上传参考图,将会按参考图的样子去生成图片。在描述词上输入内容,点击生成即可出图。
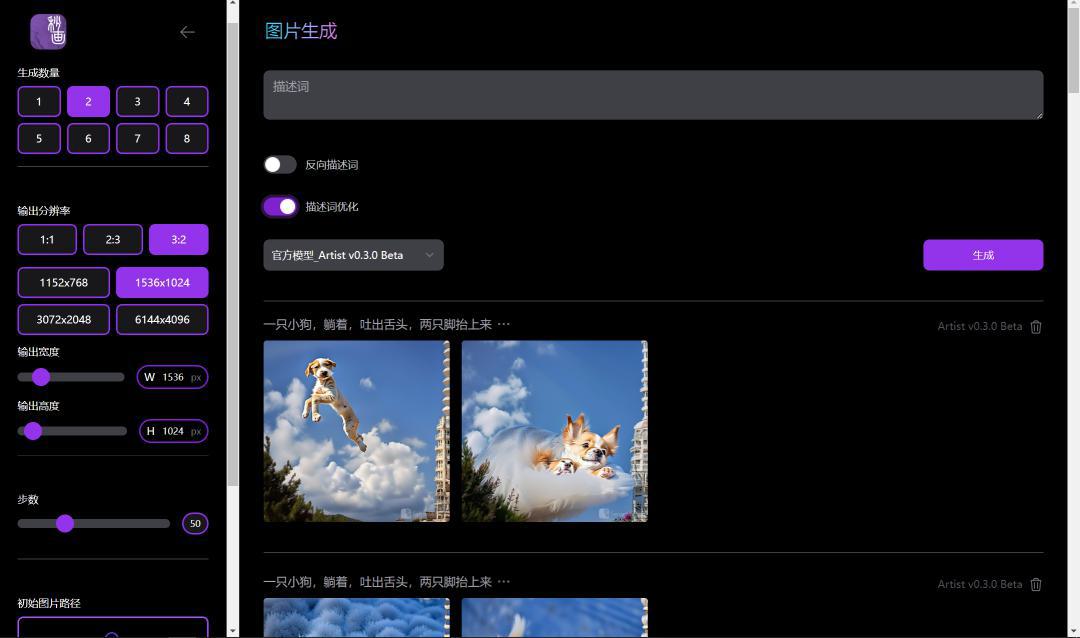
3、目前来看生成图片数量没有限制,而且可以免费使用。
4、我们还可以试下它的图片参考功能,我上传了一个图片,然后输入描述词之后,比如这个天空像一个睡毯,那么得到的效果还是很惊艳的:

通义万相
1、阿里通义万相需要先申请体验,一般要等几天审核通过,通过后会收到短信通知,即可使用了。
2、文本生成图像功能可以输入描述词,目前支持默认、水彩、油画、中国画、扁平插画、二次元、素描、3D卡通八种风格。再选择完一个图片比例后,即可出图了,一次可以生成四张图片。
3、还有相似图像生成功能,如果你有一张图片,担心侵权,但有很想用,那么可以上传图片,然后生成一张类似的图片出来,不过这种方式下不可以再输入描述词。比如刚才它生成“龙凤呈祥”效果不是很拉胯嘛,那么把商汤秒画的图作为原图,看下生成的相似图片,终于像两条龙了:

4、万相还支持“图像风格迁移”,我们可以上传一个原图,再上传一个风格图,就可以生成以风格图的绘图风格修改的原图了。这种一般可以在模仿画家风格中可以用到。比如我这么尝试了下:
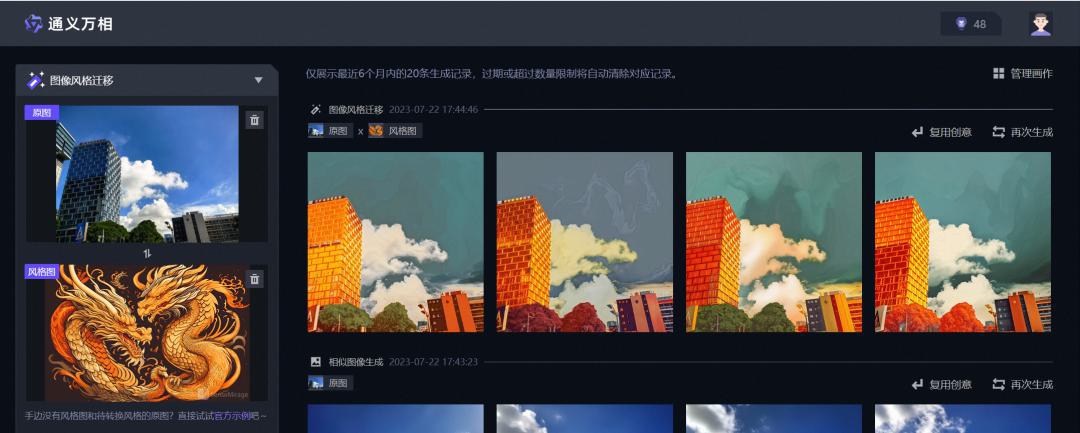
5、平台目前还在测试阶段,每天最多可以免费生成50次图,一次4张。
至于你喜欢哪一款AI绘图工具,可以自己再尝试下,选择挺多,咱们不一定要用付费的Midjourney,也可以得到不错的效果呢。
剑指 Meta:Mistral Large2 凌晨开源,媲美 Llama3.1
Overseas 发表了文章 • 2024-07-25 11:58
Mistral AI 发布 Mistral Large 2,123B 大小,128k 上下文,与 Llama 3.1 不相上下。
支持包括法语、德语、西班牙语、意大利语、葡萄牙语、阿拉伯语、印地语、俄语、中文、日语和韩语在内的数十种语言- 支持 Function Calling 和 Retrieval
开源地址: https://huggingface.co/mistralai/Mistral-Large-Instruct-2407 可用于研究和非商业用途,商用需获取许可
在线使用:https://chat.mistral.ai/chat
开发者平台:https://console.mistral.ai/
云服务:可在 Google Cloud 、Azure AI Studio、Amazon Bedrock 和 IBM watsonx.ai 上调用
简单使用
可在这里使用:https://chat.mistral.ai/chat
不够聪明啊,ahhhhhh
版本特色
- 多语言设计:支持多种语言,包括英语、法语、德语、西班牙语、意大利语、中文、日语、韩语、葡萄牙语、荷兰语和波兰语。
- 精通代码:熟练掌握 80 多种编程语言,如 Python、Java、C、C++、JavaScript 和 Bash 等。还熟悉一些更具体的语言,如 Swift 和 Fortran。
- Agent 支持:原生支持 Function Calling 和 JSON 输出。
- 好的推理:数学和推理能力远超前代,与 GPT-4o、Claude 3 Opus 和 Llama 3.1 405B 不相上下
- 128k 上下文:,加之在 la Plateforme 实施的输出限制模式,大大促进了应用开发和技术栈的现代化。
- 开源许可:允许用于研究和非商业用途的使用和修改。
推理测试
表现远超之前的 Mistral Large,与 GPT-4o、Claude 3 Opus 和 Llama 3.1 405B 相媲美
代码生成测试
MultiPL-E 性能测试
GSM8K(8-shot)和 MATH(0-shot,无 CoT)测试
语言覆盖
官方给的图,剑指 Meta
语言性能测试
更多信息
按 Mistral 的说法,他们会围绕以下模型在 la Plateforme 上进行后续整合:
- 通用模型:Mistral Nemo 和 Mistral Large
- 专业模型:Codestral 和 Embed
其中 Mistral NeMo 是一款与 NVIDIA 合作开发的 12B 模型,一周前发布的,具体参见:https://mistral.ai/news/mistral-nemo/
同时,Mistral 的 Large2 模型已可在 Google Cloud 、Azure AI Studio、Amazon Bedrock 和 IBM watsonx.ai 上进行调用。更多的安排参考:
普大喜奔!免费使用 llama3.1的八个网站
Overseas 发表了文章 • 2024-07-25 10:58
又一个重量级大模型发布,波谲云诡的AI江湖再添变数
这是一款强大的开源 AI 模型,由知名科技公司 Meta(之前叫 Facebook)发布。Llama 3.1 ,一共三个版本, 包括 8B、70B、405B
今天我向您简介这款AI,并分享八个免费使用 Llama 3.1 的方法,其中3个国内直联、支持405B!
以下是官方公布的测试数据,水平 与gpt4o、claude3.5 sonnect 旗鼓相当
第三方评测机构,除坚持用户盲测打分的LMsys暂未给出排名外,SEAL 和 Allen AI 的 ZeroEval 两个独立评估机构给出了自己的结果,405B 确实厉害!SEAL 上405B指令遵循主流AI中第一、代码第四、数学第二
ZeroEval 测试它整体性能介于 Sonnet 3.5 和 GPT4o 之间。
官方博客: llama.meta.com/llama3
申请下载: llama.meta.com/llama-downloads
一、开源 AI 和闭源 AI 大战
在 AI 的世界里,有两个阵营:开源 AI 和闭源 AI。开源 AI 像是一个巨大的图书馆,任何人都可以进去学习、分享和改进知识。闭源 AI 则像是私人图书馆,只有特定的人才能进入。什么是开源呢?就是代码和数据是公开透明的,任何人都可以下载使用和改进。开源 AI 模型和普通商业 AI 模型不太一样。开源的好处是,大家可以一起分享知识,互相合作改进模型。成本也会更低,让更多人和小型公司参与进来。而且开源的模型更加透明,人们更容易相信和信任。相比之下,商业 AI 模型的代码和数据都是保密的,只有公司自己掌控,定价也更高。但这样可以提供更专业定制的服务。
开源 AI 的优势:
共享与协作:全球的研究者和开发者可以一起工作,让模型变得更好。
SEAL 上405B指令遵循主流AI中第一、代码第四、数学第二
ZeroEval 测试它整体性能介于 Sonnet 3.5 和 GPT4o 之间。
官方博客: llama.meta.com/llama3
硬件配置 要求中等,下载到本地,苹果M1、16G显卡就能本地运行后,免费使用!
让我们一起来看看 llama3.1是如何改变游戏规则的,以及我们个人用户如何能够使用它。
关键是,如果你有能力本地部署,它还是完全免费的!
在 AI 的世界里,有两个阵营:开源 AI 和闭源 AI。
什么是开源呢?就是代码和数据是公开透明的,任何人都可以下载使用和改进。
相比之下,商业 AI 模型的代码和数据都是保密的,只有公司自己掌控,定价也更高。但这样可以提供更专业定制的服务。
- 共享与协作:全球的研究者和开发者可以一起工作,让模型变得更好。
- 成本效益:不需要很多钱就能使用这些模型,小公司和个人也能参与。
- 透明度:我们知道它是如何工作的,这让我们更信任它。
主流AI大模型速度-性能- 价格分布图如下:
闭源 AI 的特点:
- 专有技术:由一家公司控制,他们不告诉别人它是怎么做的。
- 定制化服务:可以提供特别为你设计的服务。
- 盈利模式:通过订阅费或授权使用费来赚钱。
常见闭源软件有 ChatGPT、Claude、谷歌 gemini、kimi 等
meta 是一个商业盈利机构,但是为了构建元宇宙,它买了最多的显卡,给大家训练了一个开源 AI 大模型 llama 系列!
二、llamma3 的使用
现在,让我们看看如何使用 llama3.1。
(一)本地使用:
- ollma 部署:如果你想在自己的电脑上使用 llama3,可以下载模型并进行本地部署。
1、安装和启动 Ollma
访问 https://ollama.com/download
下载适合自己系统的 Ollma 客户端。
2、运行 Ollma 客户端,它会在本地启动一个 API 服务。
在 Ollma 中,可以选择运行 LLaMA 3.1 模型
打开终端,输入:ollama run llama3.1
3、输入问题,开始使用
本地API使用 :
到第三方去购买API,然后在本机安装一个chatnextweb软件。
第三方API的价格目前是gpt4o的50%,大概2.5~3美元每百万token。
(二)在线使用
1、Meta 官网
国内直联:否
登录难度:极大
登录网址:www.meta.ai
响应速度:中等
2、抱抱脸 HuggingChat(推荐)
国内直联:否
登录难度:中
登录网址:huggingface.co/chat/
响应速度:中等
打开界面上的“设置”齿轮,选中 LLaMA3.1,点击“Activate”,输入系统提示“用中文回复”,关闭窗口,搞定!
3、Groq 平台
Groq 是一家专注于开发高效能 AI 推理硬件的公司,其产品旨在为机器学习工作负载提供高性能和低功耗的解决方案,开发了一种名为LPU的专用芯片,专门针对大型语言模型(LLM)的推理进行优化。
国内直联:否
登录难度:中
登录网址:console.groq.com
响应速度:中等
使用界面:
需要选中 LLaMA-3.1,405B暂时下架,估计过两天会恢复
4、deepinfra 平台
DeepInfra 是一个提供机器学习模型和基础设施的平台,它专注于提供快速的机器学习推理(ML Inference)服务。注册送1.5美元API 额度。也可在线使用
国内直联:否
登录难度:中
登录网址:deepinfra.com/meta-llama/
响应速度:中等
使用界面:
5、cloudflare 平台(国内直联)
Cloudflare 是一家大名鼎鼎提供互联网安全、性能优化和相关服务的公司
国内直联:是
登录难度:中
登录网址:
playground.ai.cloudflare.com/
响应速度:中等
使用界面:
需要选中 LLaMA-3.1 ,目前只有 8B 版本
6、Repilcate 平台(推荐,国内直联)
国内一个面向机器学习和人工智能模型的在线平台,专注于提供模型的部署、运行和训练服务
国内直联:是 :)
登录难度:小,国内直联,支持405B
登录网址:llama3.replicate.dev
https://replicate.com/meta/meta-llama-3-70b-instruct
响应速度:中等
使用界面:
需要选中 LLaMA-3.1
7、英伟达平台(国内直联)
英伟达公司不用介绍了吧
国内直联:是 :)
登录难度:小,,国内直联,支持405B
登录网址:
https://build.nvidia.com/explore/discover#llama-3_1-405b-instruct
响应速度:中等
使用界面:
需要选中 LLaMA-3.1
8、中文 llama 社区(国内直联)
中文 llama 社区
国内直联:是 :)
登录难度:小,国内直联,支持405B
登录网址:llama.family/chat
响应速度:70B(8B 很快)
使用界面:
这次 llama3.1 的发布,就看其他厂商如何应对了,估计 AI之王 GPT5 快出关了!
好啦,今天的分享就到这里!
Google 全新 AI 模型「Gemini」推出,30 项测试都赢过 GPT-4v,比专家还强
newsman 发表了文章 • 2023-12-25 18:03
Google 的 Bard AI 机器人过去曾使用 LaMDA 系列的语言模型,后来改为 PaLM2,如今正式宣布推出自家的语言模型 Gemini,使用 TPU v4 和 v5e 芯片进行训练,强调多模、多样化的解析能力以及运行效率,甚至在多项测试中赢过 OpenAI 的 GPT-4 模型。
Google 自家原生 AI 模型,多项测试赢过 GPT-4v
Gemini 是 Google 推出的「原生」AI 模型,可以处理包含代码、文本、声音、图片、影片这些不同形式的内容,而且因为 Google 的数据库中有着巨量的内容,是训练 Gemini 很棒的资源。
Google 甚至表示 Gemini 可以直接「看懂」图片,而不是像过去使用 OCR 的方式扫描图片然后再辨识上面的文本这种方式来分析图片。
在 Google 的影片中,拿了两张图片做比较,Gemini 可以回答右边图片中的汽车会跑的比较快,因为符合空气力学的关系,但你可以注意到,图片中并没有任何的文本,如果使用传统 OCR 解析图片的方式,就无法判断出这些内容。
Google 展示的内容中,甚至还直接画了一只鸭子,而 Gemini 也可以很快地理解出用户话的内容是什么。
Gemini 也能够解析代码、C++、Java 等常用编程语言,甚至是爬虫都可以,不只分析,也能够按照你要的需求、指定的语言生成代码。
Gemini 的运行速度也相当快,在一个午休的时间就可以阅读完 20 万份的论文,并且从用户要求的关键字、条件去查找相关的数据,找出 250 份符合资格的论文以及我们要找的数据在哪里,并且整理成一份清单。
如果拿来和 OpenAI 的 GPT-4v 和 Gemini 做比较,全部 32 项测试中,有 30 项测试是由 Gemini 胜过了 GPT-4v,而且在 MMLU 大规模多任务语言理解的测试中,包含了历史、法律、医学、数学….等 57 个科目中,Gemini 都有达到 90% 的水准,甚至超越了人类专家的表现。
Gemini 也有适合手机使用的版本,Pixel 8 Pro 优先体验
Gemini 共有 3 种不同大小的模型版本,分为 Ultra、Pro、Nano,其中的 Nano 版本最小,甚至可以直接安装到手机上使用,Google 也表示 Nano 版本就针对行动设备所打造的,旗下 Pixel 8 Pro 也会优先开放使用。
其中最大型的 Gemini Ultra 也就是上面所说,在 32 项测试中赢过 GPT-4v 其中 30 项的大型版本,预计明年推出,但在此之前将会先提供给部分用户、开发者以及企业用户。
而中型的 Pro 版本则是现在就可以使用,部分使用英文语系的用户在使用 Bard 的时候,就会自动用上 Gemini 模型,12/13 Google Cloud 的 Vertex AI、AI Studio 上也会释放出相关的 API。
国内AI绘图工具大PK:商汤秒画、阿里通义万相和百度文心一格,谁的绘图效果更惊艳?
newsman 发表了文章 • 2023-07-24 17:42
最近我也在试用国内AI大模型方面做得比较好的另外两家的AI文生图产品,他们就是商汤秒画和阿里通义万相,他们都是可以免费注册后使用的,使用起来没太多限制,很方便。再结合我之前推荐的百度文心一格也是免费的,今天咱们就来对比PK一下国内目前这三家的AI绘图能力,看谁画出来的图更好呢。
商汤秒画的访问地址是:https://miaohua.sensetime.com/zh-CN
通义万相的访问地址是:https://wanxiang.aliyun.com/
文心一格的访问地址是:https://yige.baidu.com/
好了,大家可以试下注册,注册好之后我们就来开始试用吧。
绘画技能PK
我们用一样的描述词,来看下三款工具的绘图效果。
1、先试下简短的词语:森林里的精灵
首先是商汤秒画的效果:
接下来是通义万相出场:
最后是文心一格出场:
这一轮,大家都把自己心目中的精灵画出来了,难分伯仲。
2、好,那第二轮换一个词:黑夜,北极星发出一束光照射到大海上,杰作,细节丰富,8K,HDR
商汤秒画:
通义万相:
文心一格:
也还是仁者见仁智者见智,各有优势。
3、再来一轮PK,描述词:万马奔腾
商汤秒画:
通义万相:
文心一格:
个人评价,这轮秒画后面许多马有些失真,万相的扬沙效果做得更好,而文心虽然马的细节做得挺好,但是没有画出万马的感觉。
3、再来一个需要一定的知识储备的吧,描述词:武松打虎。
商汤秒画:
通义万相:
文心一格:
这轮很明显,只有秒画get到了意思,万相有点闹着玩啊,文心至少画出了老虎,这轮秒画胜出。
4、之前看过网友用Midjourney生成各个朝代士兵自拍的图片,挺逼真的,这是效果图,今天我们也拿这三个国产AI绘图工具也来试试看,看跟目前最棒的AI工具的差距还有多少。
描述词:公元前1000年,一个秦朝的士兵对着镜头在自拍,穿着盔甲,开心地笑,旁边围着一群士兵,面对镜头也在笑,背景是城墙,上面飘着秦朝的大旗,杰作,细节丰富,HDR,8K画质
商汤秒画:
通义万相:
文心一格:
这轮看来,文心偏得有些多呀,秒画和万相虽然感觉不太像秦朝的士兵服装(我们通过秦始皇兵马俑的着装可以找到原版),但整体摄影感觉还是比较真实的。
5、最后,我们来试试他们的家居设计能力。描述词:现代简约家居设计,一个客厅,桌子,电视,茶几,阳台,沙发
商汤秒画:
通义万相:
文心一格:
整体来讲,都get到了描述词的点,但是个人观点,万相输出的设计更符合主流设计风格,电视机的摆放更合理些。
下面我来分别介绍下这三款AI绘图的使用方法:
商汤秒画
1、我们登录进来后,选择Artist v0.3.0 Beta模型进行绘画,这个是官方团队出品的。至于其他模型,是用户自己再通过一些特定数据集进行训练后的,有些擅长画水墨画、有些擅长出游戏人物,有的擅长画小人书,这个看个人需求。从通用性角度来看,还是官方模型效果最好。
2、我们可以选择一次生成的图片数量、分辨率比例、步数一般设置到最大100,画质效果最好。也可以上传参考图,将会按参考图的样子去生成图片。在描述词上输入内容,点击生成即可出图。
3、目前来看生成图片数量没有限制,而且可以免费使用。
4、我们还可以试下它的图片参考功能,我上传了一个图片,然后输入描述词之后,比如这个天空像一个睡毯,那么得到的效果还是很惊艳的:
通义万相
1、阿里通义万相需要先申请体验,一般要等几天审核通过,通过后会收到短信通知,即可使用了。
2、文本生成图像功能可以输入描述词,目前支持默认、水彩、油画、中国画、扁平插画、二次元、素描、3D卡通八种风格。再选择完一个图片比例后,即可出图了,一次可以生成四张图片。
3、还有相似图像生成功能,如果你有一张图片,担心侵权,但有很想用,那么可以上传图片,然后生成一张类似的图片出来,不过这种方式下不可以再输入描述词。比如刚才它生成“龙凤呈祥”效果不是很拉胯嘛,那么把商汤秒画的图作为原图,看下生成的相似图片,终于像两条龙了:
4、万相还支持“图像风格迁移”,我们可以上传一个原图,再上传一个风格图,就可以生成以风格图的绘图风格修改的原图了。这种一般可以在模仿画家风格中可以用到。比如我这么尝试了下:
5、平台目前还在测试阶段,每天最多可以免费生成50次图,一次4张。
至于你喜欢哪一款AI绘图工具,可以自己再尝试下,选择挺多,咱们不一定要用付费的Midjourney,也可以得到不错的效果呢。
剑指 Meta:Mistral Large2 凌晨开源,媲美 Llama3.1
Overseas 发表了文章 • 2024-07-25 11:58
Mistral AI 发布 Mistral Large 2,123B 大小,128k 上下文,与 Llama 3.1 不相上下。
支持包括法语、德语、西班牙语、意大利语、葡萄牙语、阿拉伯语、印地语、俄语、中文、日语和韩语在内的数十种语言- 支持 Function Calling 和 Retrieval
开源地址: https://huggingface.co/mistralai/Mistral-Large-Instruct-2407 可用于研究和非商业用途,商用需获取许可
在线使用:https://chat.mistral.ai/chat
开发者平台:https://console.mistral.ai/
云服务:可在 Google Cloud 、Azure AI Studio、Amazon Bedrock 和 IBM watsonx.ai 上调用
简单使用
可在这里使用:https://chat.mistral.ai/chat
不够聪明啊,ahhhhhh
版本特色
- 多语言设计:支持多种语言,包括英语、法语、德语、西班牙语、意大利语、中文、日语、韩语、葡萄牙语、荷兰语和波兰语。
- 精通代码:熟练掌握 80 多种编程语言,如 Python、Java、C、C++、JavaScript 和 Bash 等。还熟悉一些更具体的语言,如 Swift 和 Fortran。
- Agent 支持:原生支持 Function Calling 和 JSON 输出。
- 好的推理:数学和推理能力远超前代,与 GPT-4o、Claude 3 Opus 和 Llama 3.1 405B 不相上下
- 128k 上下文:,加之在 la Plateforme 实施的输出限制模式,大大促进了应用开发和技术栈的现代化。
- 开源许可:允许用于研究和非商业用途的使用和修改。
推理测试
表现远超之前的 Mistral Large,与 GPT-4o、Claude 3 Opus 和 Llama 3.1 405B 相媲美
代码生成测试
MultiPL-E 性能测试
GSM8K(8-shot)和 MATH(0-shot,无 CoT)测试
语言覆盖
官方给的图,剑指 Meta
语言性能测试
更多信息
按 Mistral 的说法,他们会围绕以下模型在 la Plateforme 上进行后续整合:
- 通用模型:Mistral Nemo 和 Mistral Large
- 专业模型:Codestral 和 Embed
其中 Mistral NeMo 是一款与 NVIDIA 合作开发的 12B 模型,一周前发布的,具体参见:https://mistral.ai/news/mistral-nemo/
同时,Mistral 的 Large2 模型已可在 Google Cloud 、Azure AI Studio、Amazon Bedrock 和 IBM watsonx.ai 上进行调用。更多的安排参考:
普大喜奔!免费使用 llama3.1的八个网站
Overseas 发表了文章 • 2024-07-25 10:58
又一个重量级大模型发布,波谲云诡的AI江湖再添变数
这是一款强大的开源 AI 模型,由知名科技公司 Meta(之前叫 Facebook)发布。Llama 3.1 ,一共三个版本, 包括 8B、70B、405B
今天我向您简介这款AI,并分享八个免费使用 Llama 3.1 的方法,其中3个国内直联、支持405B!
以下是官方公布的测试数据,水平 与gpt4o、claude3.5 sonnect 旗鼓相当
第三方评测机构,除坚持用户盲测打分的LMsys暂未给出排名外,SEAL 和 Allen AI 的 ZeroEval 两个独立评估机构给出了自己的结果,405B 确实厉害!SEAL 上405B指令遵循主流AI中第一、代码第四、数学第二
ZeroEval 测试它整体性能介于 Sonnet 3.5 和 GPT4o 之间。
官方博客: llama.meta.com/llama3
申请下载: llama.meta.com/llama-downloads
一、开源 AI 和闭源 AI 大战
在 AI 的世界里,有两个阵营:开源 AI 和闭源 AI。开源 AI 像是一个巨大的图书馆,任何人都可以进去学习、分享和改进知识。闭源 AI 则像是私人图书馆,只有特定的人才能进入。什么是开源呢?就是代码和数据是公开透明的,任何人都可以下载使用和改进。开源 AI 模型和普通商业 AI 模型不太一样。开源的好处是,大家可以一起分享知识,互相合作改进模型。成本也会更低,让更多人和小型公司参与进来。而且开源的模型更加透明,人们更容易相信和信任。相比之下,商业 AI 模型的代码和数据都是保密的,只有公司自己掌控,定价也更高。但这样可以提供更专业定制的服务。
开源 AI 的优势:
共享与协作:全球的研究者和开发者可以一起工作,让模型变得更好。
SEAL 上405B指令遵循主流AI中第一、代码第四、数学第二
ZeroEval 测试它整体性能介于 Sonnet 3.5 和 GPT4o 之间。
官方博客: llama.meta.com/llama3
硬件配置 要求中等,下载到本地,苹果M1、16G显卡就能本地运行后,免费使用!
让我们一起来看看 llama3.1是如何改变游戏规则的,以及我们个人用户如何能够使用它。
关键是,如果你有能力本地部署,它还是完全免费的!
在 AI 的世界里,有两个阵营:开源 AI 和闭源 AI。
什么是开源呢?就是代码和数据是公开透明的,任何人都可以下载使用和改进。
相比之下,商业 AI 模型的代码和数据都是保密的,只有公司自己掌控,定价也更高。但这样可以提供更专业定制的服务。
- 共享与协作:全球的研究者和开发者可以一起工作,让模型变得更好。
- 成本效益:不需要很多钱就能使用这些模型,小公司和个人也能参与。
- 透明度:我们知道它是如何工作的,这让我们更信任它。
主流AI大模型速度-性能- 价格分布图如下:
闭源 AI 的特点:
- 专有技术:由一家公司控制,他们不告诉别人它是怎么做的。
- 定制化服务:可以提供特别为你设计的服务。
- 盈利模式:通过订阅费或授权使用费来赚钱。
常见闭源软件有 ChatGPT、Claude、谷歌 gemini、kimi 等
meta 是一个商业盈利机构,但是为了构建元宇宙,它买了最多的显卡,给大家训练了一个开源 AI 大模型 llama 系列!
二、llamma3 的使用
现在,让我们看看如何使用 llama3.1。
(一)本地使用:
- ollma 部署:如果你想在自己的电脑上使用 llama3,可以下载模型并进行本地部署。
1、安装和启动 Ollma
访问 https://ollama.com/download
下载适合自己系统的 Ollma 客户端。
2、运行 Ollma 客户端,它会在本地启动一个 API 服务。
在 Ollma 中,可以选择运行 LLaMA 3.1 模型
打开终端,输入:ollama run llama3.1
3、输入问题,开始使用
本地API使用 :
到第三方去购买API,然后在本机安装一个chatnextweb软件。
第三方API的价格目前是gpt4o的50%,大概2.5~3美元每百万token。
(二)在线使用
1、Meta 官网
国内直联:否
登录难度:极大
登录网址:www.meta.ai
响应速度:中等
2、抱抱脸 HuggingChat(推荐)
国内直联:否
登录难度:中
登录网址:huggingface.co/chat/
响应速度:中等
打开界面上的“设置”齿轮,选中 LLaMA3.1,点击“Activate”,输入系统提示“用中文回复”,关闭窗口,搞定!
3、Groq 平台
Groq 是一家专注于开发高效能 AI 推理硬件的公司,其产品旨在为机器学习工作负载提供高性能和低功耗的解决方案,开发了一种名为LPU的专用芯片,专门针对大型语言模型(LLM)的推理进行优化。
国内直联:否
登录难度:中
登录网址:console.groq.com
响应速度:中等
使用界面:
需要选中 LLaMA-3.1,405B暂时下架,估计过两天会恢复
4、deepinfra 平台
DeepInfra 是一个提供机器学习模型和基础设施的平台,它专注于提供快速的机器学习推理(ML Inference)服务。注册送1.5美元API 额度。也可在线使用
国内直联:否
登录难度:中
登录网址:deepinfra.com/meta-llama/
响应速度:中等
使用界面:
5、cloudflare 平台(国内直联)
Cloudflare 是一家大名鼎鼎提供互联网安全、性能优化和相关服务的公司
国内直联:是
登录难度:中
登录网址:
playground.ai.cloudflare.com/
响应速度:中等
使用界面:
需要选中 LLaMA-3.1 ,目前只有 8B 版本
6、Repilcate 平台(推荐,国内直联)
国内一个面向机器学习和人工智能模型的在线平台,专注于提供模型的部署、运行和训练服务
国内直联:是 :)
登录难度:小,国内直联,支持405B
登录网址:llama3.replicate.dev
https://replicate.com/meta/meta-llama-3-70b-instruct
响应速度:中等
使用界面:
需要选中 LLaMA-3.1
7、英伟达平台(国内直联)
英伟达公司不用介绍了吧
国内直联:是 :)
登录难度:小,,国内直联,支持405B
登录网址:
https://build.nvidia.com/explore/discover#llama-3_1-405b-instruct
响应速度:中等
使用界面:
需要选中 LLaMA-3.1
8、中文 llama 社区(国内直联)
中文 llama 社区
国内直联:是 :)
登录难度:小,国内直联,支持405B
登录网址:llama.family/chat
响应速度:70B(8B 很快)
使用界面:
这次 llama3.1 的发布,就看其他厂商如何应对了,估计 AI之王 GPT5 快出关了!
好啦,今天的分享就到这里!
Google 全新 AI 模型「Gemini」推出,30 项测试都赢过 GPT-4v,比专家还强
newsman 发表了文章 • 2023-12-25 18:03
Google 的 Bard AI 机器人过去曾使用 LaMDA 系列的语言模型,后来改为 PaLM2,如今正式宣布推出自家的语言模型 Gemini,使用 TPU v4 和 v5e 芯片进行训练,强调多模、多样化的解析能力以及运行效率,甚至在多项测试中赢过 OpenAI 的 GPT-4 模型。
Google 自家原生 AI 模型,多项测试赢过 GPT-4v
Gemini 是 Google 推出的「原生」AI 模型,可以处理包含代码、文本、声音、图片、影片这些不同形式的内容,而且因为 Google 的数据库中有着巨量的内容,是训练 Gemini 很棒的资源。
Google 甚至表示 Gemini 可以直接「看懂」图片,而不是像过去使用 OCR 的方式扫描图片然后再辨识上面的文本这种方式来分析图片。
在 Google 的影片中,拿了两张图片做比较,Gemini 可以回答右边图片中的汽车会跑的比较快,因为符合空气力学的关系,但你可以注意到,图片中并没有任何的文本,如果使用传统 OCR 解析图片的方式,就无法判断出这些内容。
Google 展示的内容中,甚至还直接画了一只鸭子,而 Gemini 也可以很快地理解出用户话的内容是什么。
Gemini 也能够解析代码、C++、Java 等常用编程语言,甚至是爬虫都可以,不只分析,也能够按照你要的需求、指定的语言生成代码。
Gemini 的运行速度也相当快,在一个午休的时间就可以阅读完 20 万份的论文,并且从用户要求的关键字、条件去查找相关的数据,找出 250 份符合资格的论文以及我们要找的数据在哪里,并且整理成一份清单。
如果拿来和 OpenAI 的 GPT-4v 和 Gemini 做比较,全部 32 项测试中,有 30 项测试是由 Gemini 胜过了 GPT-4v,而且在 MMLU 大规模多任务语言理解的测试中,包含了历史、法律、医学、数学….等 57 个科目中,Gemini 都有达到 90% 的水准,甚至超越了人类专家的表现。
Gemini 也有适合手机使用的版本,Pixel 8 Pro 优先体验
Gemini 共有 3 种不同大小的模型版本,分为 Ultra、Pro、Nano,其中的 Nano 版本最小,甚至可以直接安装到手机上使用,Google 也表示 Nano 版本就针对行动设备所打造的,旗下 Pixel 8 Pro 也会优先开放使用。
其中最大型的 Gemini Ultra 也就是上面所说,在 32 项测试中赢过 GPT-4v 其中 30 项的大型版本,预计明年推出,但在此之前将会先提供给部分用户、开发者以及企业用户。
而中型的 Pro 版本则是现在就可以使用,部分使用英文语系的用户在使用 Bard 的时候,就会自动用上 Gemini 模型,12/13 Google Cloud 的 Vertex AI、AI Studio 上也会释放出相关的 API。
国内AI绘图工具大PK:商汤秒画、阿里通义万相和百度文心一格,谁的绘图效果更惊艳?
newsman 发表了文章 • 2023-07-24 17:42
最近我也在试用国内AI大模型方面做得比较好的另外两家的AI文生图产品,他们就是商汤秒画和阿里通义万相,他们都是可以免费注册后使用的,使用起来没太多限制,很方便。再结合我之前推荐的百度文心一格也是免费的,今天咱们就来对比PK一下国内目前这三家的AI绘图能力,看谁画出来的图更好呢。
商汤秒画的访问地址是:https://miaohua.sensetime.com/zh-CN
通义万相的访问地址是:https://wanxiang.aliyun.com/
文心一格的访问地址是:https://yige.baidu.com/
好了,大家可以试下注册,注册好之后我们就来开始试用吧。
绘画技能PK
我们用一样的描述词,来看下三款工具的绘图效果。
1、先试下简短的词语:森林里的精灵
首先是商汤秒画的效果:
接下来是通义万相出场:
最后是文心一格出场:
这一轮,大家都把自己心目中的精灵画出来了,难分伯仲。
2、好,那第二轮换一个词:黑夜,北极星发出一束光照射到大海上,杰作,细节丰富,8K,HDR
商汤秒画:
通义万相:
文心一格:
也还是仁者见仁智者见智,各有优势。
3、再来一轮PK,描述词:万马奔腾
商汤秒画:
通义万相:
文心一格:
个人评价,这轮秒画后面许多马有些失真,万相的扬沙效果做得更好,而文心虽然马的细节做得挺好,但是没有画出万马的感觉。
3、再来一个需要一定的知识储备的吧,描述词:武松打虎。
商汤秒画:
通义万相:
文心一格:
这轮很明显,只有秒画get到了意思,万相有点闹着玩啊,文心至少画出了老虎,这轮秒画胜出。
4、之前看过网友用Midjourney生成各个朝代士兵自拍的图片,挺逼真的,这是效果图,今天我们也拿这三个国产AI绘图工具也来试试看,看跟目前最棒的AI工具的差距还有多少。
描述词:公元前1000年,一个秦朝的士兵对着镜头在自拍,穿着盔甲,开心地笑,旁边围着一群士兵,面对镜头也在笑,背景是城墙,上面飘着秦朝的大旗,杰作,细节丰富,HDR,8K画质
商汤秒画:
通义万相:
文心一格:
这轮看来,文心偏得有些多呀,秒画和万相虽然感觉不太像秦朝的士兵服装(我们通过秦始皇兵马俑的着装可以找到原版),但整体摄影感觉还是比较真实的。
5、最后,我们来试试他们的家居设计能力。描述词:现代简约家居设计,一个客厅,桌子,电视,茶几,阳台,沙发
商汤秒画:
通义万相:
文心一格:
整体来讲,都get到了描述词的点,但是个人观点,万相输出的设计更符合主流设计风格,电视机的摆放更合理些。
下面我来分别介绍下这三款AI绘图的使用方法:
商汤秒画
1、我们登录进来后,选择Artist v0.3.0 Beta模型进行绘画,这个是官方团队出品的。至于其他模型,是用户自己再通过一些特定数据集进行训练后的,有些擅长画水墨画、有些擅长出游戏人物,有的擅长画小人书,这个看个人需求。从通用性角度来看,还是官方模型效果最好。
2、我们可以选择一次生成的图片数量、分辨率比例、步数一般设置到最大100,画质效果最好。也可以上传参考图,将会按参考图的样子去生成图片。在描述词上输入内容,点击生成即可出图。
3、目前来看生成图片数量没有限制,而且可以免费使用。
4、我们还可以试下它的图片参考功能,我上传了一个图片,然后输入描述词之后,比如这个天空像一个睡毯,那么得到的效果还是很惊艳的:
通义万相
1、阿里通义万相需要先申请体验,一般要等几天审核通过,通过后会收到短信通知,即可使用了。
2、文本生成图像功能可以输入描述词,目前支持默认、水彩、油画、中国画、扁平插画、二次元、素描、3D卡通八种风格。再选择完一个图片比例后,即可出图了,一次可以生成四张图片。
3、还有相似图像生成功能,如果你有一张图片,担心侵权,但有很想用,那么可以上传图片,然后生成一张类似的图片出来,不过这种方式下不可以再输入描述词。比如刚才它生成“龙凤呈祥”效果不是很拉胯嘛,那么把商汤秒画的图作为原图,看下生成的相似图片,终于像两条龙了:
4、万相还支持“图像风格迁移”,我们可以上传一个原图,再上传一个风格图,就可以生成以风格图的绘图风格修改的原图了。这种一般可以在模仿画家风格中可以用到。比如我这么尝试了下:
5、平台目前还在测试阶段,每天最多可以免费生成50次图,一次4张。
至于你喜欢哪一款AI绘图工具,可以自己再尝试下,选择挺多,咱们不一定要用付费的Midjourney,也可以得到不错的效果呢。